When I lived in L.A. it seemed like everyone wanted to be a movie star. The Starbucks barista waiting to be discovered as he pronounced “Frappuccino,” friends scheming to be placed on a reality show and win a trip to a tropical island, and the many writers trying to get their latest script into the hands of Steven Spielberg. The recent boom in online video and its associated capture hardware has created a new class of stars. The next American Idol might submit a cover song to YouTube and video of a child’s first steps are uploading to the Web for the world to see. How can search engines discover these new sources of video, extract relevant information, and successfully handle user queries? In this post I will take a look at the present state of video search, how machines make sense out of movies, and take a peek inside the state of the art.

A multiplexed video file contains a set of sequenced pictures with an accompanying audio track. Digital video often adds a header describing the recorded work to assist in playback and location. Due to a video’s composition many technologies from image search and audio search still apply, but with a few optimizations to take advantage of a larger amount of correlated data.
File identification
A general search engine contains links from all over the Web, including links to video files. A specialized video index may be formed by combing through a link index looking for links adhering to known file extensions:
- avi
- Audio Video Interleave, an older format popular on Windows machines.
- mov
- qt
- QuickTime container, popular on Apple computers.
- mp4
- m4v
- MPEG-4 Part 14 files. M4V is a popular expression used by Apple’s iTunes.
- wmv
- Windows Media video.
- asf
- Streaming video using Microsoft technologies. The Advanced Streaming Format is not exclusive to video as it may contain streaming audio.
- flv
- Adobe Flash videos.
- divx
- DivX Media Format
- 3gp
- 3g2
- 3G mobile phone format
- rm
- RealVideo format by RealNetworks.
- mpg
- mpeg
- MPEG-1 or MPEG-2 video file.
- ogm
- Theora video format.
Windows Live Search allows users to restrict searches to pages containing links to files containing one or more file extensions, such as a search for mov, wmv, or m4v files on pages mentioning “dance.” Bookmarking site del.icio.us uses this method to identify video bookmarked by its users.
HTML markup
Links
Video found in the wild are often described and referenced within HTML pages. Here’s an example of how an audio file might be described within a web page link:
<a href="firststeps.mov"
type="video/quicktime"
hreflang="en-us"
title="A longer description of the target video">
A short description</a>
The href attribute points to the location of the video file. The video/quicktime type value provides a hint for user agents about the type of file on the other end of the link. The hreflang attribute communicates the base language of the linked content. The title attribute provides more information about the linked resource, and may be displayed as a tooltip in some browsers. The element value, “A short description,” is the linked text on the page.
It’s not very likely publishers will produce more data than the functional effort of href. Title is a semi-visible attribute and therefore more likely to be included in the description, but still uncommon. It’s possible to identify video by a given MIME type such as video/quicktime but few sites provide the advisory hint of type in their HTML markup. Collecting a file’s MIME type requires “touching” the remote file, and will most likely return default values of popular hosting applications such as Apache or IIS, so a search engine is likely better off relying on a local list of mapped extensions and helper application behaviors.
Embeds
Some videos are embedded in the page, complete with plugin handler descriptions that allow a webpage viewer to play back the audio file directly from its page context. This content may take the form of an object or an embed in the page markup. The old-style embed element seems to be preferred by the autogenerated HTML of popular video sites, presumably for backwards compatibility with more web browsers. Embedded content often specifies a preferred handler plugin and possibly a “movie” parameter, but it’s difficult to tell from the markup if the referenced file is a video.
A search engine may apply special handling to embeds from well known video hosts to gather link data for resource discovery and ranking. A YouTube video embed references the same identifier used to construct the URL of the full web page, and could be counted towards that page’s total citations.
Syndication formats
It is possible for a publisher to provide more information about a video item and its alternate formats using a syndication format namespace extension such as Yahoo! Media RSS. Details such as bitrate, framerate, audio channels, rating, thumbnail, total duration, and even acting credits can be applied to information about the remote resource without actually “touching” the file. This method is currently used by large publishers such as CNN to provide Yahoo! with constant updates for its sites.
Producers of Quicktime, MPEG-4, or H.264 video may provide more information about their content using Apple’s podcasting namespace. Extra information such as subtitle, total duration, rating, thumbnail, and keywords may be associated with video content using this namespace. This data is displayed in the iTunes Store and by other compatible applications.
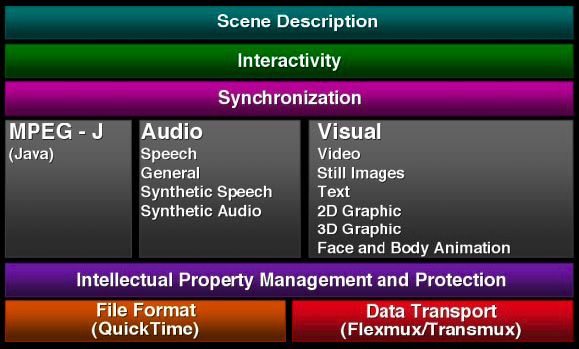
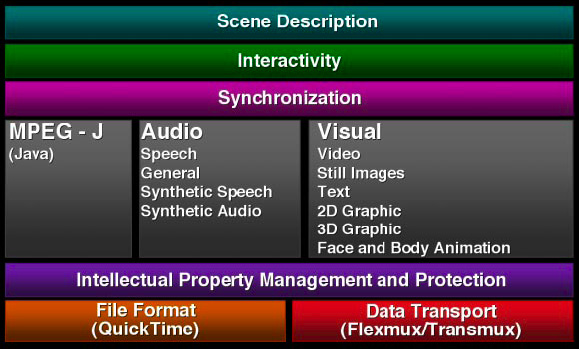
MPEG-4 video (
drawing by Apple)
Video files are packaged in specialized containers containing header data and video content encoded in what could be multiple different codecs per container type. The drawing above is an example of the multiple components of MPEG-4 from descriptive elements to the audio and video tracks, and the synchronization to bring it all together. Information such as title, description, author and copyright are common and similar to an MP3’s ID3 information. Additional data such as encoding format, frame rate, duration, height and width, and language may be included.
Descriptors such as MPEG-7 can be applied to the entire file, or applied to just the audio or video track. A publisher may also describe a sub-section of a video with more information, such as a nightly news report containing descriptors for each individual segment.
The Library of Congress maintains a directory on video formats aimed at preserving digital moving images and their descriptions throughout time. It’s an interesting browse if you’re into that sort of thing.
Subtitles
A video may contain timed text, otherwise known as subtitles. This information can be described using 3GPP Timed Text, for hearing impaired, language translation, karaoke, or many other uses. Search engines may use this data to easily gather more information about the track.
Hosted video
File size and bandwidth constraints of individual web hosts make specialized video hosting an attractive (and often free) option. Google will host your video files on Google Video or YouTube, Yahoo! hosts video at Yahoo! Video, and Microsoft has MSN Soapbox. Hosted video standardizes video formats for easy playback, extracts metadata at the time of upload, and collects ranking data such as popularity and derivative works through its user communities.
Video hosting handles many of the current limitations of video sharing. Encoding is normalized and optimized with little noticeable difference to the casual user. Flash Video is a common hosted playback method thanks to the ubiquity of Adobe’s Flash player, but hosts will use higher-quality video where appropriate such as Windows Video on MSN Soapbox or DivX on Stage6.
A hosted video contains its own web page with additional captured (and public) data such as author, page views, category, tags, ratings, and comments. Ratings and other commentary is especially interesting because it allows a site to construct a social network around a particular publisher, learning about their likes and dislikes.
Watching the movie
A movie is a series of still frames in sequence. A sampling of frames reveals context, such as recognizing the actors in a particular scene, the backdrop, or when that Coke bottle appeared during a television show. Image analysis outlined in my image search post can be applied to videos and used to better determine context combined with other available information such as audio.
Parsing spoken word
Video indexers can listen to the audio track and parse the spoken word in much the same way as stand-alone audio search. The presence of images provides additional context than pure audio and provides an extended yet focused vocabulary for comparison. Matching your pronunciation of “cappuccino” to the visual cues and sounds of a cafe assist in speech recognition. Similarly, the presence of a football on screen provides better context for the word “goal” during your family’s weekend match.
Tracking video citations
Fingerprinting
Professional videos are often “fingerprinted” with information about the work. A video producer might include frames that are ignored by humans viewing 24-60 frames per second, but identifiable by machines watching for the data.
Television shows often have frames of text at their beginning to communicate the show title, episode number, year produced, and other data. Special frames may be used before and after a commercial to easily denote a switch from syndicated content to locally inserted media. Techniques from professional video production may find their way into more web videos, especially as amateurs begin using tools previously only within the reach of the pros.
It is also possible to fingerprint a file based on its description data, length, and other factors. A video site could “roll up” these different references and track the original source by discovery date or direct reference where available.
As videos are copied and redistributed their digital fingerprint will often remain intact, allowing indexers to recognize and attribute the piece to its original source.
Videos within videos
Videos sometimes contain citations and references to other videos. The nightly news referencing the President’s State of the Union address will use a single source of video provided by the U.S. government. References to “education reform” may then be applied and ranked based on these video citations and history of heavy citations of government videos, similar to PageRank and other methods used today for other publicly addressable resources.
Summary
Video is a busy space and I feel like I’ve only scratched the surface with this long post. Expect more companies with expertise in image and audio search to get involved in video search. The image technologies of recent Google acquisition Neven Vision have already been applied to video feeds from security cameras. The audio search technology used by BBN Technologies is now being used by PodZinger to search a video’s audio content.
You can expect to see even more technologies making their way from the security sector into consumer use as we’ve already see happen in image and audio search. Sequence neutral processing may eventually be applied to the space, replacing the multiple serialized analysis passes we have today.
Video is booming and is not going away anytime soon. Video capabilities are becoming more common in mobile phones, our capture quality continues to increase, and easy-to-use editing tools on the desktop such as iMovie put better tools in the hands of the average user. Video sharing used to involve recording to a VHS or DVD for sharing with friends but is now as easy as a menu option within an editing application or uploading via a web form on a popular hosting site. The growth of media-hungry sites MySpace and YouTube have proved the built-in audience waiting for new content. The cat videos, karaoke, short films, and breaking news reports will continue to roll in, creating a need for better search and discovery. Hopefully the search industry is up to the challenge and will continue to surface new and relevant information to an eager audience.