A few more details about Google’s possible analysis of page text is now available thanks to a recently published patent application by Googler Anna Patterson from June 2006. The application details how a search engine like Google might analyze text phrases, date-based topics, and associate a web page with related topics, even if the specific topic does not appear in the document itself. The 22-page document further emphasizes Google’s current work on “shingle” analysis to discover important phrases and concepts. (via Search Engine Land)
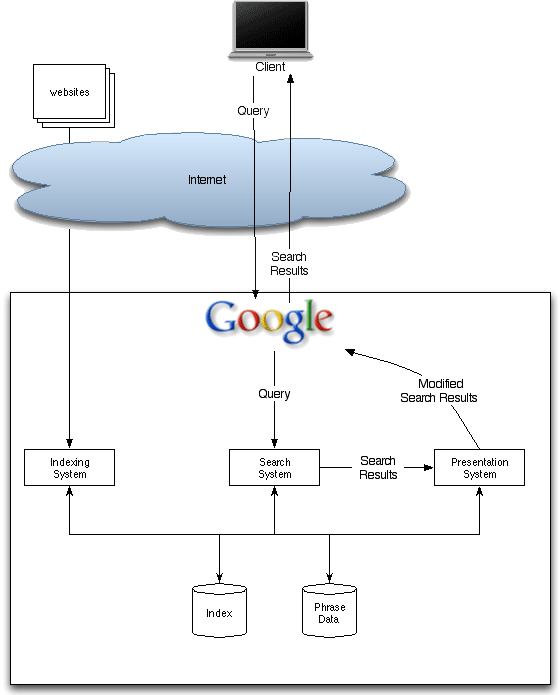
Highly ranked websites are more likely to receive in-depth analysis through multiple index passes and phrase associations. Factors such as PageRank, count weights, and type weights might grant a page admission to further analysis and a secondary relevance index based on phrase data.
The phrase indexer passes over a document to determine key phrases and contextual themes throughout. If your web page contains references to a specific date the indexer might limit its vocabulary to a surrounding date range, but otherwise the index date and similar web pages are used to build a vocabulary of common and rare phrases with good and bad descriptions and extensions of these phrase concepts. A website publisher might influence key phrases on a page using grammatical or markup formatting such as bold, underline, anchor text, or quotation marks.
Once key phrases are identified it is possible to identify related terms and phrases within the same document. If you use the phrase “President Bill Clinton” and later reference “President Clinton,” “Mr. Clinton,” or even just the word Clinton, there are statistical correlations between the occurrence of each phrase referencing the same topic or person. If the phrase “Monica Lewinsky” is mentioned there is a 99.999% chance the document references Bill Clinton in some way, based on the total number of documents and Lewinsky references currently on the web. Probabilities increase if “Monica Lewinsky” appears in a document published or referencing the time period of 1995 through 1998.
A web page’s rank for a given phrase degrades over time as Google prefers to deliver the most recently relevant information for any given query. There are some exceptions mentioned, such as a historical site consistently referenced from pages containing date references, which will help boost the ranking of an older resource.
These phrase analysis techniques can be used to identify spam. The indexer will look at the occurrence of a phrase or theme compared against an expected set of good and possible matches. If the page or subsection of a page appears to be too heavily weighted toward a specific subject, well beyond the commonly observed usage, the page is flagged as a highly probable spam source.
Conclusion
Citation-based ranking and analysis is the most commonly mentioned search function but PageRank is just one of many factors influencing search results beyond the original Google concepts from 10 years ago.
As search indexes grow by the billions web publishers are increasingly exposed to multiple tiers of analysis through multiple proving rounds. Once a new site graduates from the sandbox it will need to find its way into secondary index analysis, enhanced image search, and much much more. It’s pretty cool stuff if you’re a search geek, but the millions of regular users will simply watch the gears of distributed search engine backends crank around the world, returning 10 results of greatest interest.