When I lived in L.A. it seemed like everyone wanted to be a movie star. The Starbucks barista waiting to be discovered as he pronounced “Frappuccino,” friends scheming to be placed on a reality show and win a trip to a tropical island, and the many writers trying to get their latest script into the hands of Steven Spielberg. The recent boom in online video and its associated capture hardware has created a new class of stars. The next American Idol might submit a cover song to YouTube and video of a child’s first steps are uploading to the Web for the world to see. How can search engines discover these new sources of video, extract relevant information, and successfully handle user queries? In this post I will take a look at the present state of video search, how machines make sense out of movies, and take a peek inside the state of the art.
A multiplexed video file contains a set of sequenced pictures with an accompanying audio track. Digital video often adds a header describing the recorded work to assist in playback and location. Due to a video’s composition many technologies from image search and audio search still apply, but with a few optimizations to take advantage of a larger amount of correlated data.
File identification
A general search engine contains links from all over the Web, including links to video files. A specialized video index may be formed by combing through a link index looking for links adhering to known file extensions:
avi
Audio Video Interleave, an older format popular on Windows machines.
Video found in the wild are often described and referenced within HTML pages. Here’s an example of how an audio file might be described within a web page link:
<a href="firststeps.mov"
type="video/quicktime"
hreflang="en-us"
title="A longer description of the target video">
A short description</a>
The href attribute points to the location of the video file. The video/quicktimetype value provides a hint for user agents about the type of file on the other end of the link. The hreflang attribute communicates the base language of the linked content. The title attribute provides more information about the linked resource, and may be displayed as a tooltip in some browsers. The element value, “A short description,” is the linked text on the page.
It’s not very likely publishers will produce more data than the functional effort of href. Title is a semi-visible attribute and therefore more likely to be included in the description, but still uncommon. It’s possible to identify video by a given MIME type such as video/quicktime but few sites provide the advisory hint of type in their HTML markup. Collecting a file’s MIME type requires “touching” the remote file, and will most likely return default values of popular hosting applications such as Apache or IIS, so a search engine is likely better off relying on a local list of mapped extensions and helper application behaviors.
Embeds
Some videos are embedded in the page, complete with plugin handler descriptions that allow a webpage viewer to play back the audio file directly from its page context. This content may take the form of an object or an embed in the page markup. The old-style embed element seems to be preferred by the autogenerated HTML of popular video sites, presumably for backwards compatibility with more web browsers. Embedded content often specifies a preferred handler plugin and possibly a “movie” parameter, but it’s difficult to tell from the markup if the referenced file is a video.
A search engine may apply special handling to embeds from well known video hosts to gather link data for resource discovery and ranking. A YouTube video embed references the same identifier used to construct the URL of the full web page, and could be counted towards that page’s total citations.
Syndication formats
It is possible for a publisher to provide more information about a video item and its alternate formats using a syndication format namespace extension such as Yahoo! Media RSS. Details such as bitrate, framerate, audio channels, rating, thumbnail, total duration, and even acting credits can be applied to information about the remote resource without actually “touching” the file. This method is currently used by large publishers such as CNN to provide Yahoo! with constant updates for its sites.
Producers of Quicktime, MPEG-4, or H.264 video may provide more information about their content using Apple’s podcasting namespace. Extra information such as subtitle, total duration, rating, thumbnail, and keywords may be associated with video content using this namespace. This data is displayed in the iTunes Store and by other compatible applications.
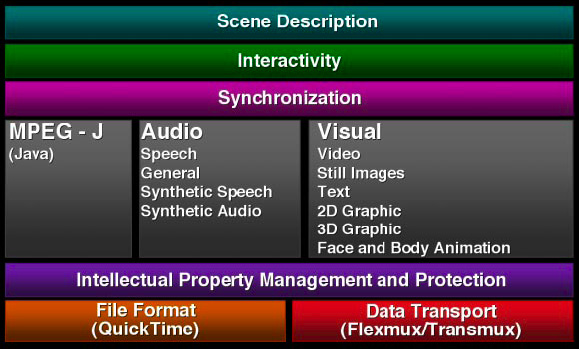
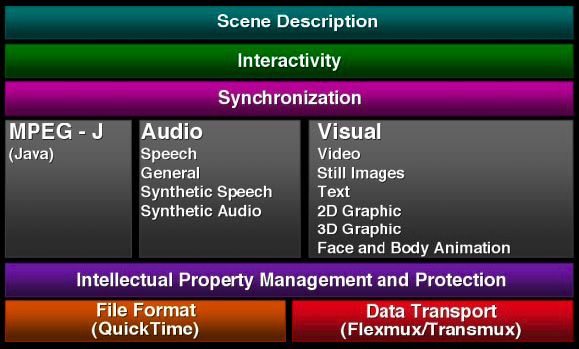
Video files are packaged in specialized containers containing header data and video content encoded in what could be multiple different codecs per container type. The drawing above is an example of the multiple components of MPEG-4 from descriptive elements to the audio and video tracks, and the synchronization to bring it all together. Information such as title, description, author and copyright are common and similar to an MP3’s ID3 information. Additional data such as encoding format, frame rate, duration, height and width, and language may be included.
Descriptors such as MPEG-7 can be applied to the entire file, or applied to just the audio or video track. A publisher may also describe a sub-section of a video with more information, such as a nightly news report containing descriptors for each individual segment.
A video may contain timed text, otherwise known as subtitles. This information can be described using 3GPP Timed Text, for hearing impaired, language translation, karaoke, or many other uses. Search engines may use this data to easily gather more information about the track.
Hosted video
File size and bandwidth constraints of individual web hosts make specialized video hosting an attractive (and often free) option. Google will host your video files on Google Video or YouTube, Yahoo! hosts video at Yahoo! Video, and Microsoft has MSN Soapbox. Hosted video standardizes video formats for easy playback, extracts metadata at the time of upload, and collects ranking data such as popularity and derivative works through its user communities.
Video hosting handles many of the current limitations of video sharing. Encoding is normalized and optimized with little noticeable difference to the casual user. Flash Video is a common hosted playback method thanks to the ubiquity of Adobe’s Flash player, but hosts will use higher-quality video where appropriate such as Windows Video on MSN Soapbox or DivX on Stage6.
A hosted video contains its own web page with additional captured (and public) data such as author, page views, category, tags, ratings, and comments. Ratings and other commentary is especially interesting because it allows a site to construct a social network around a particular publisher, learning about their likes and dislikes.
Watching the movie
A movie is a series of still frames in sequence. A sampling of frames reveals context, such as recognizing the actors in a particular scene, the backdrop, or when that Coke bottle appeared during a television show. Image analysis outlined in my image search post can be applied to videos and used to better determine context combined with other available information such as audio.
Parsing spoken word
Video indexers can listen to the audio track and parse the spoken word in much the same way as stand-alone audio search. The presence of images provides additional context than pure audio and provides an extended yet focused vocabulary for comparison. Matching your pronunciation of “cappuccino” to the visual cues and sounds of a cafe assist in speech recognition. Similarly, the presence of a football on screen provides better context for the word “goal” during your family’s weekend match.
Tracking video citations
Fingerprinting
Professional videos are often “fingerprinted” with information about the work. A video producer might include frames that are ignored by humans viewing 24-60 frames per second, but identifiable by machines watching for the data.
Television shows often have frames of text at their beginning to communicate the show title, episode number, year produced, and other data. Special frames may be used before and after a commercial to easily denote a switch from syndicated content to locally inserted media. Techniques from professional video production may find their way into more web videos, especially as amateurs begin using tools previously only within the reach of the pros.
It is also possible to fingerprint a file based on its description data, length, and other factors. A video site could “roll up” these different references and track the original source by discovery date or direct reference where available.
As videos are copied and redistributed their digital fingerprint will often remain intact, allowing indexers to recognize and attribute the piece to its original source.
Videos within videos
Videos sometimes contain citations and references to other videos. The nightly news referencing the President’s State of the Union address will use a single source of video provided by the U.S. government. References to “education reform” may then be applied and ranked based on these video citations and history of heavy citations of government videos, similar to PageRank and other methods used today for other publicly addressable resources.
Summary
Video is a busy space and I feel like I’ve only scratched the surface with this long post. Expect more companies with expertise in image and audio search to get involved in video search. The image technologies of recent Google acquisition Neven Vision have already been applied to video feeds from security cameras. The audio search technology used by BBN Technologies is now being used by PodZinger to search a video’s audio content.
You can expect to see even more technologies making their way from the security sector into consumer use as we’ve already see happen in image and audio search. Sequence neutral processing may eventually be applied to the space, replacing the multiple serialized analysis passes we have today.
Video is booming and is not going away anytime soon. Video capabilities are becoming more common in mobile phones, our capture quality continues to increase, and easy-to-use editing tools on the desktop such as iMovie put better tools in the hands of the average user. Video sharing used to involve recording to a VHS or DVD for sharing with friends but is now as easy as a menu option within an editing application or uploading via a web form on a popular hosting site. The growth of media-hungry sites MySpace and YouTube have proved the built-in audience waiting for new content. The cat videos, karaoke, short films, and breaking news reports will continue to roll in, creating a need for better search and discovery. Hopefully the search industry is up to the challenge and will continue to surface new and relevant information to an eager audience.
Online audio is definitely on an upswing, fueled by the iPod revolution, improved online playback, and broadband penetration. Audio search is keeping up with demand for new content, thanks in part to national security spending in the Cold War and beyond. In this post I will outline the current state of audio search, and how machines make sense of spoken word, progressing from easy to difficult.
First, let’s define the space. I’m interested how a search engine might index content with non-professionally produced metadata. The President’s weekly radio address contains a full transcript. Music catalogs are available for purchase from Muze and others to provide structured data about Bob Dylan and what he’s saying. A voicemail message or a podcast might not be as thoroughly described.
Let’s take a look at audio files a search engine might discover during a web crawl and current methods of understanding the content.
Filetype identification
Audio content can be broken down into a few unique file extensions that hint at the remote audio container.
wav
The waveform audio format is a common form of uncompressed audio on Windows PCs.
aiff
The Audio Interchange File Format is a common form of uncompressed audio on Apple computers.
mp3
MPEG-1 Audio Layer 3 is a popular form of distribution for compressed audio files.
Audio files found in the wild are often described and referenced from within HTML pages. Here’s an example of how an audio file might be described within a web page link:
<a href="speech.mp3"
type="audio/mpeg"
hreflang="en-us"
title="A longer description of the target audio">
A short description</a>
The href attribute points to the location of the audio file. The audio/mpegtype value provides a hint for user agents about the type of file on the other end of the link. The hreflang attribute communicates the base language of the linked content. The title attribute provides more information about the linked resource, and may be displayed as a tooltip in some browsers. The element value, “A short description,” is the linked text on the page.
It’s not very likely publishers will produce more data than the functional effort of href. Title is a semi-visible attribute and therefore more likely to be included in the description, but still uncommon. It’s possible to identify audio by a given MIME type such as audio/mpeg but few sites provide the advisory hint of type in their HTML markup. Collecting a file’s MIME type requires “touching” the remote file, and will most likely return default values of popular hosting applications such as Apache or IIS, so a search engine is likely better off relying on a local list of mapped extensions and helper application behaviors.
Syndication formats
It is possible for a publisher to include more information about a file using a syndication feed combined with a specialized namespace such as the iTunes podcasting spec or Yahoo! Media RSS. A search engine may parse these feeds to gather more information about a particular audio item such as title, description, and length, which often provides a closer correlation than an audio link present on a web page.
Hosted audio
Large search engines such as Google, Yahoo!, and Microsoft have not created the same sort of hosted audio community for user-generated content as is present in images or video. Sites such as the Internet Archive host audio such as a Grateful Dead concert complete with data such as artist, title, performance date, equipment used, and audio editors.
Apple’s GarageBand software is one example of integrated recording, compression, descriptive markup, and remote hosting.
Metadata containers
Once you reach out and “touch” the audio file the search engine can discover more description information embedded within. An ID3 tag describes the track title, artist, album, genre, and other information provided by the publisher. The metadata descriptor might contain additional information such as album art, lyrics, or descriptions specific to a specific segment of the audio file described as “chapters.” An audio metadata parser takes a look at each frame it knows how to read to extract the associated descriptive data.
ID3 tags often occur at the beginning of the file to assist streaming applications and a metadata indexer might not grab the entire audio file, opting instead to only look for data in those first bytes.
Parsing spoken word
Speech recognition has enjoyed rapid improvement over the last decade, thanks in part to the large budgets of national security indexing spoken words captured through ECHELON and other methods. Similar technology is now being applied to medical and legal transcriptions and creating more searchable content for each podcast.
Speech-to-text software such as AVOKE from BBN Technologies is used to create transcripts of phone calls to call centers, the nightly news, and government surveillance. The system utilizes known vocabularies by language applied over a continuous density hidden Markov model to analyze speech phonemes in various contexts. The system uses multiple passes to determine context and associative clustering of words and phrases.
Spoken word analysis is utilized in consumer search engine PodZinger to track a search term and jump to the appropriate marker within the file containing the given term. You can search for audio containing mentions of the Athletics and Tigers and view your results in the context of the file with direct links to that segment of the audio program.
Summary
Online audio content will only continue to get bigger, as more content makes its way online and into the ears of consumers on a PC, iPod, or other listening device. The maturity of online audio and the current business feasibility should consolidate audio format offerings into audio understood by dominant market players in the desktop, portable, and home theater markets.
I expect even more speech-to-text work in the future as the CPUs, memory, and disk space available continues to become computationally and monetarily cheaper. Perhaps we might even see client-side analysis of content similar to analysis work being conducted on images. Windows Media Player and iTunes are just two examples of popular media players that connect to the Internet to retrieve more information about your media files, from album art to recorded year. In the future such applications might also query data services such as Last.fm, MusicBrainz, or the Music Genome Project to apply more data to each file based on a purchased database, collective intelligence, or expert analysis.
Creating new sources of audio content is becoming easier. The popularity of VoIP will place new value on microphones connected to our PCs, gaming systems, and other connected electronics devices. Voice will become an integrated feature, allowing you to easily save a compressed audio file of a recent planning call or your Halo trash-talking session.
I think many search engines have looked past audio search due to the litigious nature of the RIAA and others evidenced by last year’s MGM vs. Grokster Supreme Court ruling. Google’s recent $1.65 billion purchase of YouTube is perhaps a sign that search technology will continue to advance, challenging any emergent legal roadblocks along the way.
As with most search sectors, audio search is still in very early stages. Expect known vocabularies and relationship mappings to increase over time, providing more insight not only into each word, but also speaker identification, tone, and possibly even relationships between events such as a power outage’s correlation to customer service calls. We’ll keep talking and publishing and search will attempt to keep up with our rate of speech, accents, and methods of describing our creations.
A picture is worth a thousand words, especially to search engines trying to match a brief search query to a set of appropriate visual results. How can a web search engine collect enough data about a particular image to provide a user with relevant results? In this post I will outline image search concepts, the current state of the art, and outline some of the challenges with still image search.
Image on your website
You might recognize the depiction above as Yoda, a popular character the Star Wars movie series. More specifically this is a picture of a Yoda statue perched on top of a fountain at Lucasfilm’s headquarters in San Francisco. Here’s what Yoda might look like expressed on a web page.
The above markup communicates a few attributes of the image the publisher would like to display using the img element of (x)HTML. A publisher will specify the location of the file but the other attributes are often not used to add further information about the image.
I’ve provided a few extra pieces of data in my example. The alt attribute provides a brief description and is used by browsers as a placeholder while the image is retrieved, if it can be retrieved at all. The longdesc attribute links to a URL with a longer description of the image. The width and height of the image is described in pixels, and all values are provided in English. This extra data is uncommonly used, although XHTML requires both the location of the file (src) and a brief description (alt).
Most search engines utilize the file name as an approximate descriptor of the image. A digital still camera will create serial file names such as DSC001.jpg, making things much worse!
Hosted image libraries
How do image hosting sites provided by major search engines change the ability to search your latest still image? Yahoo!’s Flickr and Google’s Picasa encourage users to add extra descriptors to images to enable better discoverability and sharing. The description data is more visible than standard HTML markup, making that DSC0001.jpg image title look pretty ugly. Any Flickr-hosted photo displayed in another web page must also include a link to the full Flickr photo page, thereby creating a long description of the image for all search engines.
My Flickr photo page of Yoda contains a short description, long description, a set of keywords provided by me and/or other site users, and metadata extracted from the image file such as the date and time reading on the digital still image device on capture. Other data such as geographic coordinates may be extracted and displayed on this page, or I might take a few extra steps to manually add the metadata.
The popularity of a particular photo measured by the hosting site complements other ranking factors such as page- and author-level link ranks. Data gathering possibilities are defined by the manual data input of each user as well as the information present at time of capture and edit. It’s very easy for a search service such as Yahoo! or Google to reach out and “touch” these images stored just a short fiber down the rack.
External citations
The image may also be described by links from other websites to the hosted page or the image itself. In this case image search can use similar citation analysis as traditional web search to note how other publishers reference a particular resource.
Touching the image
A few more pieces of data are available to indexers once they take a peek inside the actual image file. Date and time of capture, camera settings, location, and copyright data may be described in formats such as Exif or XMP, adding even more context.
Date and time
Most digital image capture devices include a clock and timestamp their photos. The time available on a mobile phone syncs over-the-air and generally more reliable than a typical digital camera which requires additional setup and menu navigation.
Geolocation
Where in the world did you take that photo? Mobile phones are delivering better location-aware services with each new release, fueled by government demand for better emergency services for mobile customers and the industry’s desire to capitalize on location-aware service offerings. Some phones include an actual GPS receiver while others rely on the same cell tower triangulation that helps deliver a call to your handset.
A standalone GPS can synchronize its coordinates with a stand-alone digital camera based on the timestamp on each device. A bicyclist with a GPS receiver and a stand-alone digital point-and-shoot can combine data from each gadget and plot their entire bike ride complete with pictures.
A WiFi-enabled camera can ping nearby access points to approximate its current location using location data provided by the access point or by comparing the access point’s digital fingerprint against a mapped database such as Microsoft Virtual Earth.
Copyright data
A publisher may describe a photo’s copyright in plain text or by pointing to a URL with more information. If that URL is Creative Commons it’s pretty easy to parse license terms.
Machine viewing
Text
An indexer might take a look at the photo and try to analyze its depictions. Pictured above is the drink menu from Stumptown Coffee Roasters in Portland, Oregon with lots of text. If a machine could recognize the words “espresso” and “latte” in the picture it could build a richer data set for this image. The same technology is useful for decoding image headers found in web pages and for testing CAPTCHA images designed to be parsed by humans, not machines.
People, places, things
Facial-recognition technology can identify the same photo subject across multiple photo captures by analyzing patterns across common facial attributes. The technology is used by security systems, such as comparing World Cup attendees against a list of known troublemakers. A photo publisher can install software on their desktop computer to analyze each photograph looking for people, places, and things familiar to that person or the software’s larger community. The software can then identify things such as a previously identified person such as the boy pictured above, a picture of the Eiffel Tower already identified by other users of the software, or a Coke bottle present in a photo.
Google acquired Neven Vision in August to boost their ability to extract information from image depictions. Riya is working on image recognition technology applied to image search.
Summary
A search engine has a variety of data available when trying to make sense of a particular image. The most reliable data comes from auto-configured machines, but humans can supplement and correct this data if they choose to involve themselves in the process. Advances in capture hardware and software will continue to add more valuable metadata surrounding the photo, allowing a search engine to better understand the image with less text from the publisher.
The biggest area for search advancement currently lies in image analysis for text, people, places, and things. National security budgets are currently funding advanced research in this area that will hopefully trickle down to the consumer sector to help us better identify our family photo collections without repetitive data input.
The Bluetooth SIG announced wireless transfer of contact, calendar, and notes information via what it’s calling TransSend. It implements the OBEX standard you may have used to “beam” someone your contact information in the past. You can send vCard, vCal, vNote, plain text, or image files from a PC to supporting handsets.
An ActiveX plugin for Internet Explorer lets users send content from a web page to their mobile phone. You can send driving directions, your contact info, or event data.
Sounds cool, but it looks like the plugin is relying on proprietary markup for recognition instead of using something like microformat markup. According to Phone Scoop not many U.S. have an open OBEX profile, further limiting the usefulness of the extra markup.
The first ever conference dedicated to widgets, gadgets, and modules will take place on Monday, November 6, in San Francisco. The one-day conference will capture and summarize the emerging widget economy and allow developers, business leaders, and content producers to collaborate and better understand how they might participate in syndication at the edge of the network.
A small web loosely joined.
I am organizing a conference named Widgets Live! next month in partnership with Om Malik to capture the emerging webspace of widgets. There’s so much happening in the fast-moving widget space right now it’s a bit difficult to keep track of it all. Feed your Chia Pet on your desktop. Let your blog visitors play Hangman using popular words of the day. Consult your calendar from your homepage. Check the weather from your coffee maker. There is so much activity in the customizable web powered by widgets we felt it was time to bring together the major players for a one-day industry overview and tutorial. We hope you can join us.
Tickets are only $100 and available now. I’ll blog more details about what it’s like to plan a conference and the decisions made by organizers at a later date as everyone I’ve talked to so far has been intrigued at the behind-the-scenes operations of the industry, from $13 for a cup of coffee to the real reasons why conference WiFi is often horrible. The faster the conference sells out the more time I’ll have for those posts! ;)
The event takes place at Microsoft’s Silicon Valley campus starting at 6:30 p.m. If you’re in the area and have an interest in search or video come by and check out the crowd and presentations.
I’ll be down in Silicon Valley for most of the day, visiting Google for lunch and settling into a cafe (most likely Barefoot Coffee Roasters) for the afternoon.
Google shocked the online world this weekend with its acquisition of leading video site YouTube for $1.65 billion in Google stock. YouTube will maintain its brand and site, and move into its new San Bruno offices this week as planned. Hitwise estimates YouTube’s market share in September at 46%, an even stronger share in Europe. Google Video had an estimated market share of 11% in the same period.
The $1.65 billion acquisition places YouTube at about the same purchase price adjusted for inflation as eBay’s acquisition of PayPal in 2002 for $1.5 billion. I’m sure the similarities are not lost on the founders and board members formerly of PayPal. I think the acquisition price is absolutely nuts.
While Google Video has been a popular destination for copyrighted videos such as NBA basketball or Nickelodeon cartoons YouTube has become the hub for all things video. Users create videos specifically for videos and its audience and publishers cross-post their work just to tap into the sheer volume of YouTube watchers. The most popular videos from other sites often make their way to YouTube, including copyrighted works such as Daily Show clips or the latest soccer highlights.
YouTube is a mass-market play for Google and differentiated from its paid distribution system highlighted by Google Video. The acquisition delivers millions of pageviews with Google high CPMs delivered through Google’s targeting abilities and video advertising inventory. According to the Wall Street Journal Google’s Eric Schmidt and Advertising title=”Vice President”>VP Tim Armstrong will meet with News Corp. Chairman Rupert Murdoch, President Peter Chernin and Fox Interactive head Ross Levinsohn later this week to discuss Google integration with MySpace and I’m sure YouTube will be a hot topic of discussion.
YouTube launched on December 15, 2005, ten months after the co-founders registered the domain name. Chad Hurley was a former designer at PayPal and Steve Chen was still employed at eBay as a software engineer. The PayPal alumni network served them well, leading to two venture rounds from former PayPal CFO Roelof Botha at Sequoia Capital. Hedge fund Artis Capital Management and Wilson Sonsini Goodrich & Rosati lawyer Stephen Welles also participated in the B round.
Timeline
I’ve put together an interactive timeline detailing the history of YouTube from the day the first founder quit PayPal until today’s acquisition. Each event is clickable and a few contain links to more information. Enjoy!
We’ve never presented MOVABLE TYPE as the program that will revolutionize weblogging.
We’re just developing a system with a lot of the features that we’ve heard users are looking for.
Luckily, we’ve received a lot of good word of mouth. People are hoping that MT will be THE program and THE solution.
A brief history
Movable Type launched Six Apart, a company that originally made money through paid custom installs, donations, and commercial licenses. The company later hosted its own version of Movable Type named TypePad, selling monthly subscriptions and licensing the hosted group blogging software to companies around the world. Six Apart bought LiveJournal in January 2005. Six Apart has recently been working on Vox, its first blogging software written from scratch with the resources of a 125-person company.
Happy birthday Movable Type and Six Apart. Five years seems like such a long time looking back before the multiple VC rounds, women baring their breasts in protest outside the office, Christmas parties, and over 100 employees around the world.
Internet Explorer will be released in just a few weeks, pushed to Windows XP users as a critical update. The Windows RSS Platform ships as part of IE7 and will likely become the most popular desktop aggregator by the end of the year. Are you ready for the switchover?
There are changes to CSS and JavaScript handling and an OpenSearch search box you should probably code against if you would like quick and easy access to your site and its archive. I’m mainly interested in the changes in feed syndication so I’ll walk through some areas that might trip you up as a publisher.
Valid XML only
Is your feed valid XML? If you or your customers are outputting content with invalid characters, an undefined namespace, or a non-breaking space ( ) the Windows RSS Platform will disregard your feed updates. A snapshot of Google Reader’s subscriptions last December found about 7% of the feeds it indexes are not well-formed XML.
Use modern feed formats
The platform includes support for feed formats RSS 2.0, RSS 1.0, Atom 1.0. If you are still outputting in RSS 0.91, RSS 0.92, or Atom 0.3 IE7 will still support the format, but you are encouraged to upgrade to a more recent feed format for the best support. Feeds that reference a DTD are considered a potential security issue and the feed parser will reject the feed and display an error message.
Auto-discovery
Can web browsers easily find your feeds? Internet Explorer 7 tries to auto-discover feeds referenced as a link alternate in your HTML. IE7 mimics Firefox’s auto-discovery behavior, so if you notice your feed(s) lighting chicklets in Firefox you should be all set. Your web server can help identify feeds by serving the correct MIME types for each feed type such as application/atom+xml or text/xml. Browsers take a number of steps when trying to identify your feed. If you produce better output the browser does less work!
Check for valid feed names
Do you have a valid feed name? The Windows RSS Platform supports feed names between 1 and 120 characters in length and may not contain a back-slash (“”) or Unicode control characters in range 0-31.
Check for valid feed markup
The Feed Validator can help you find more issues in your feeds that might cause problems for feed parsers. The feed validator project is open-source and you can run your own local copy using Python.
Google publishes the last 5 minutes of ping activity in its changes.xml file. It is possible to receive pings of different recency by adding the last parameter to your request with a number of seconds between 1 and 300.
The new service is a change in Google’s view of the web, accepting the value of fresh index content within minutes instead of waiting for the regular polling schedule.